Reklāma
Dažos pēdējos mēnešos jūs, iespējams, esat lasījis apkārtējo informāciju raksts, kura autors ir Stīvens Hokings, apspriežot riskus, kas saistīti ar mākslīgo intelektu. Rakstā tika ierosināts, ka AI var radīt nopietnu risku cilvēcei. Hokings tur nav viens pats - Elons Musks un Pēteris Thiels ir gan intelektuālas sabiedriskās personas, kuras ir izteikušas līdzīgas bažas (Thiel ir ieguldījis vairāk nekā USD 1,3 miljonus, pētot šo jautājumu un iespējamos risinājumus).
Hokinga raksts un Muska komentāri ir atspoguļoti, lai to neuzliktu pārāk smalki, tas ir nedaudz dzīvespriecīgs. Tonis ir bijis ļoti daudz "Paskatieties uz šo dīvaino lietu, par kuru visi šie geeks uztraucas." Maza uzmanība tiek pievērsta idejai, ka, ja daži no visgudrākajiem cilvēkiem uz Zemes brīdina jūs, ka kaut kas varētu būt ļoti bīstams, tas vienkārši ir vērts ieklausīties.
Tas ir saprotams - mākslīgais intelekts, pārņemot pasauli, noteikti izklausās ļoti dīvaini un neticami, varbūt tāpēc, ka zinātniskā fantastika jau ir pievērsusi milzīgu uzmanību šai idejai rakstnieki. Tātad, ko visi šie nomināli saprātīgie, racionālie cilvēki ir tik ļoti uzmundrinājuši?
Kas ir intelekts?
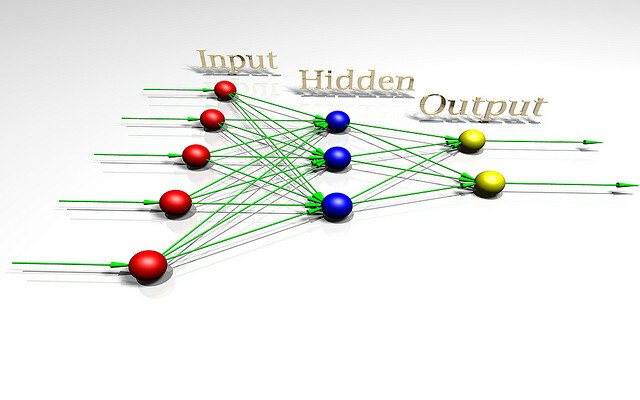
Lai runātu par mākslīgā intelekta bīstamību, varētu būt noderīgi saprast, kas ir intelekts. Lai labāk izprastu šo jautājumu, apskatīsim rotaļlietu AI arhitektūru, ko izmanto pētnieki, kuri pēta spriešanas teoriju. Šo rotaļlietu AI sauc par AIXI, un tai ir vairākas noderīgas īpašības. Tā mērķi var būt patvaļīgi, tas labi sader ar skaitļošanas jaudu, un tā iekšējais dizains ir ļoti tīrs un skaidrs.
Turklāt jūs varat ieviest vienkāršas, praktiskas arhitektūras versijas, kas var darīt tādas lietas kā spēlēt Pacman, Ja tu vēlies. AIXI ir AI pētnieka Marcus Hutter produkts, kurš, iespējams, ir galvenais algoritmiskās intelekta eksperts. Tas ir par viņu, kas runā augstāk esošajā videoklipā.
AIXI ir pārsteidzoši vienkāršs: tam ir trīs galvenās sastāvdaļas: audzēknis, plānotājs, un lietderības funkcija.
- audzēknis ņem bitu virknes, kas atbilst ievadam par ārpasauli, un meklē caur datorprogrammām, līdz atrod tādas, kas savus novērojumus rada kā izejas. Šīs programmas kopā ļauj izdarīt minējumus par to, kāda izskatīsies nākotne, vienkārši palaižot katru no tām programmas priekšu un rezultāta varbūtības svērumu pēc programmas ilguma (Occam’s ieviešana Skuveklis).
- plānotājs meklē iespējamās darbības, kuras aģents varētu veikt, un izmanto apmācāmo moduli, lai paredzētu, kas notiks, ja tas prasītu katru no tiem. Pēc tam tos vērtē pēc tā, cik labi vai slikti ir prognozētie rezultāti, un izvēlas kursu darbība, kas palielina paredzamā rezultāta labumu, kas reizināts ar paredzamo varbūtību to sasniedzot.
- Pēdējais modulis lietderības funkcija, ir vienkārša programma, kas apraksta nākotnes pasaules stāvokli un aprēķina tam lietderības rādītāju. Šis lietderības rādītājs norāda, cik labs vai slikts ir šis rezultāts, un plānotājs to izmanto, lai novērtētu nākotnes pasaules stāvokli. Lietderības funkcija var būt patvaļīga.
- Kopumā šie trīs komponenti veido optimizētājs, kas tiek optimizēts konkrētam mērķim neatkarīgi no pasaules, kurā tas atrodas.
Šis vienkāršais modelis ir intelektuālā aģenta pamata definīcija. Aģents pēta savu vidi, veido tās modeļus un pēc tam izmanto šos modeļus, lai atrastu darbības virzienu, kas maksimāli palielina izredzes, ka tas iegūs to, ko vēlas. AIXI struktūra ir līdzīga AI, kas spēlē šahu vai citas spēles ar zināmiem noteikumiem - izņemot to, ka tā spēj izsecināt spēles noteikumus, spēlējot to, sākot no nulles zināšanām.
AIXI, ņemot vērā pietiekami daudz laika aprēķināšanai, var iemācīties optimizēt jebkuru sistēmu jebkuram mērķim, lai cik sarežģīts tas būtu. Tas parasti ir inteliģents algoritms. Ņemiet vērā, ka tas nav tas pats, kas cilvēkiem ar intelektu (bioloģiski iedvesmota AI ir pavisam cita tēma Džovanni Idili no OpenWorm: smadzenes, tārpi un mākslīgais intelektsCilvēka smadzeņu imitēšana ir veids, kā novērst, bet atklātā pirmkoda projekts ir spers svarīgus pirmos soļus, simulējot viena no vienkāršākajiem zinātnei zināmajiem dzīvniekiem neiroloģiju un fizioloģiju. Lasīt vairāk ). Citiem vārdiem sakot, AIXI, iespējams, spēs pārspēt jebkuru cilvēku pie jebkura intelektuāla uzdevuma (kuram ir piešķirta pietiekama skaitļošanas jauda), bet iespējams, ka neapzinās savu uzvaru Domāšanas mašīnas: ko neirozinātne un mākslīgais intelekts var iemācīt mums par apziņuVai mākslīgi inteliģentu mašīnu un programmatūras būve var iemācīt mums par apziņas darbību un paša cilvēka prāta būtību? Lasīt vairāk .

Kā praktiskam AI, AIXI ir daudz problēmu. Pirmkārt, tam nav iespēju atrast tās programmas, kas rada iznākumu, kas to interesē. Tas ir brutāla spēka algoritms, kas nozīmē, ka tas nav praktiski, ja nenotiek patvaļīgi jaudīgs dators, kas atrodas apkārt. Jebkura faktiskā AIXI ieviešana pēc nepieciešamības ir tuvinājums, un (šodien) parasti tā ir diezgan rupja. Tomēr AIXI sniedz mums teorētisku ieskatu par to, kā varētu izskatīties jaudīgs mākslīgais intelekts un kā tas varētu būt pamatots.
Vērtību telpa
Ja esat veicis jebkuru datorprogrammēšanu Datorprogrammēšanas pamati 101 - mainīgie un datu tipiIepazīstinājuši un nedaudz runājuši par objektorientētu programmēšanu pirms un kur tā vārdadiena nāk no, es domāju, ka ir pienācis laiks pāriet uz absolūtiem programmēšanas pamatiem, kas nav saistīti ar valodu veids. Viesnīcā ir arī: ... Lasīt vairāk , jūs zināt, ka datori ir nepatīkami, pedantiski un mehāniski burtiski. Mašīna nezina un neinteresē, ko jūs vēlaties darīt: tā dara tikai to, kas tai ir pateikts. Tas ir svarīgs jēdziens, runājot par mašīninformāciju.
Paturot to prātā, iedomājieties, ka esat izgudrojis spēcīgu mākslīgo intelektu - jūs esat nācis klajā ar gudriem algoritmiem hipotēžu ģenerēšanai, kas atbilst jūsu datiem, un laba kandidāta ģenerēšanai plāni. Jūsu AI var atrisināt vispārīgas problēmas, un to var efektīvi izdarīt, izmantojot mūsdienu datortehniku.
Tagad ir laiks izvēlēties lietderības funkciju, kas noteiks AI vērtības. Kas jums būtu jālūdz to novērtēt? Atcerieties, ka mašīna būs nepatīkami, pedantiski burtiska par jebkuru funkciju, kuru jūs tai prasīsit, lai maksimizētu, un nekad neapstāsies - tajā nav spoku mašīna, kas kādreiz “pamodīsies” un nolems mainīt lietderības funkciju, neatkarīgi no tā, cik efektivitātes uzlabojumus tā pati spriešana.
Eliezers Judkovskis ielieciet to šādā veidā:
Tāpat kā visās datorprogrammēšanās, AGI pamatproblēmas un būtiskās grūtības ir tādas, ka, ja mēs rakstām nepareizu kodu, AI automātiski nepārskatīs mūsu kodu, nenozīmēs kļūdas, izdomās, ko īsti domājām pateikt, un to arī darīs tā vietā. Neprogrammētāji dažreiz iedomājas AGI vai datorprogrammas kopumā kā analogi kalpam, kurš neapstrīdami seko rīkojumiem. Bet nav tā, ka AI ir absolūti paklausīgs uz tā kodu; drīzāk AI vienkārši ir kods.
Ja jūs mēģināt darbināt rūpnīcu un jūs sakāt mašīnai, ka tā vērtē papīra saspraužu izgatavošanu, un pēc tam ļaujat tai kontrolēt rūpnīcas robotu kopumu, jūs iespējams, atgriezīsies nākamajā dienā, lai uzzinātu, ka tam ir izbeigušās jebkādas citas izejvielas, nogalināti visi jūsu darbinieki un no viņu papīra izgatavoti saspraudes paliek. Ja, mēģinot labot jūsu nepareizo kļūdu, jūs pārprogrammējat mašīnu, lai vienkārši padarītu visus laimīgus, jūs, iespējams, atgriezīsities nākamajā dienā, lai atrastu to, ievietojot vadus cilvēku smadzenēs.

Šeit runa ir par to, ka cilvēkiem ir daudz sarežģītu vērtību, par kurām mēs domājam, ka tās netieši tiek dalītas ar citiem prātiem. Mēs vērtējam naudu, bet mēs vairāk vērtējam cilvēka dzīvību. Mēs vēlamies būt laimīgi, taču mēs to nevēlamies likt smadzenēs. Mēs nejūtam vajadzību izskaidrot šīs lietas, kad mēs dodam norādījumus citiem cilvēkiem. Tomēr jūs nevarat izdarīt šāda veida pieņēmumus, izstrādājot mašīnas lietderības funkciju. Vislabākie risinājumi vienkāršas lietderības funkcijas bez dvēseles matemātikā ir tie risinājumi, kurus cilvēki mīlētu par morāli šausminošiem.
Ļaujot inteliģentai mašīnai maksimizēt naivu utilītas funkciju, gandrīz vienmēr būs katastrofāla. Kā izteicies Oksfordas filozofs Niks Bostoms,
Mēs nevaram uzskatīt, ka superinteliģencei noteikti būs kādas no gala vērtībām, kas stereotipiski saistītas ar gudrību. un intelektuālā attīstība cilvēkos - zinātniskā zinātkāre, labvēlīgas rūpes par citiem, garīgā apgaismība un kontemplācija, atteikšanās no materiālās iespējas, gaumes pēc rafinētas kultūras vai vienkāršiem dzīves priekiem, pazemības un nesavtības, un tā tālāk.
Lai situāciju padarītu sliktāku, ir ļoti, ļoti grūti norādīt pilnīgu un detalizētu visu, ko cilvēki vērtē, sarakstu. Jautājumam ir daudz aspektu, un, pat aizmirstot vienu, tas ir potenciāli katastrofāls. Pat starp tiem, par kuriem mēs esam informēti, ir smalkumi un sarežģītība, kas apgrūtina to pierakstīšanu kā tīras vienādojumu sistēmas, kuras mēs varam dot mašīnai kā lietderības funkciju.
Daži cilvēki, izlasot to, secina, ka AI izveidošana ar lietderības funkcijām ir briesmīga ideja, un mums tie vienkārši jāprojektē savādāk. Šeit ir arī sliktas ziņas - jūs to oficiāli varat pierādīt jebkuram aģentam, kam nav kaut kas līdzvērtīgs utilītas funkcijai, nevar būt saskaņotas preferences par nākotni.
Rekursīvs sevis pilnveidošana
Viens no iepriekšminētās dilemmas risinājumiem ir nedot AI aģentiem iespēju sāpināt cilvēkus: dodiet viņiem tikai resursus, kas nepieciešami Atrisiniet problēmu tādā veidā, kā jūs to domājat atrisināt, stingri uzraugiet to un neļaujiet tai paveikt iespējas kaitēt. Diemžēl mūsu spēja kontrolēt viedās mašīnas ir ļoti aizdomīga.
Pat ja viņi nav daudz gudrāki nekā mēs, mašīnai pastāv iespēja “bootstrap” - savākt labāku aparatūru vai veikt uzlabojumus savā kodā, kas padara to vēl gudrāku. Tas varētu ļaut mašīnai pārlēkt cilvēku inteliģenci daudzkārtīgi, pārspējot cilvēkus tādā pašā nozīmē, kā cilvēki pārspēj kaķus. Pirmo reizi šo scenāriju ierosināja cilvēks vārdā I. Dž. Labi, kurš Otrā pasaules kara laikā strādāja pie Enigma kriptoanalīzes projekta kopā ar Alanu Turingu. Viņš to sauca par “intelekta eksploziju” un aprakstīja šo lietu šādi:
Ļaujiet īpaši inteliģentu mašīnu definēt kā mašīnu, kas tālu pārspēj jebkura cilvēka intelektuālās aktivitātes, lai arī cik gudras tās būtu. Tā kā mašīnu projektēšana ir viena no šīm intelektuālajām darbībām, īpaši inteliģenta mašīna varētu projektēt vēl labākas mašīnas; tad neapšaubāmi notiks “izlūkošanas sprādziens”, un cilvēka inteliģence būs tālu atpalikusi. Tādējādi pirmā īpaši inteliģentā mašīna ir pēdējais izgudrojums, kas cilvēkam jebkad ir jārada, ja vien šī mašīna ir pietiekami paklausīga.
Nav garantēts, ka izlūkošanas sprādziens ir iespējams mūsu Visumā, taču tas šķiet ticams. Laikam ejot, datori kļūst ātrāki un uzkrājas pamata atziņas par izlūkošanu. Tas nozīmē, ka nepieciešamība pēc resursiem, lai pēdējo reizi pārietu uz vispārēju, pastiprinošu izlūkošanu, pazeminās un pazeminās. Kādā brīdī mēs atradīsimies pasaulē, kurā miljoniem cilvēku var doties uz Best Buy un paņemt aparatūru un tehniskā literatūra, kas viņiem nepieciešama, lai izveidotu pašpilnveidojošu mākslīgo intelektu, kas, iespējams, jau ir ļoti izveidots bīstams. Iedomājieties pasauli, kurā jūs varētu izgatavot atombumbas no nūjām un akmeņiem. Tāda ir nākotnes veida diskusija.
Un, ja mašīna šo lēcienu izdarīs, tas intelektuālā ziņā varētu ļoti ātri pārspēt cilvēku sugas produktivitāte, risinot problēmas, kuras miljards cilvēku nespēj atrisināt, tādā pašā veidā kā cilvēki var atrisināt problēmas, kas a miljardi kaķu nevar.
Tas varētu attīstīt jaudīgus robotus (vai bio vai nanotehnoloģiju) un salīdzinoši ātri iegūt spēju pārveidot pasauli pēc savas izvēles, un mēs to darītu ļoti maz. Šāda izlūkošana varētu bez lielām grūtībām atbrīvot Zemes un pārējo Saules sistēmu rezerves daļās, dodoties uz visu, ko mēs tam teicām. Liekas, ka šāda attīstība cilvēcei būtu katastrofāla. Mākslīgajam intelektam nav jābūt ļaunprātīgam, lai iznīcinātu pasauli, tas ir vienkārši katastrofiski vienaldzīgs.
Kā saka: "Mašīna tevi nemīl un ne ienīst, bet tu esi izveidots no atomiem, kuru tā var izmantot citām lietām."
Riska novērtēšana un mazināšana
Tātad, ja mēs pieņemam, ka jaudīga mākslīgā intelekta izstrāde, kas maksimizē vienkāršu lietderības funkciju, ir slikta, cik daudz problēmu mēs patiesībā esam? Cik ilgs laiks mums ir, līdz kļūst iespējams izgatavot šāda veida mašīnas? To, protams, ir grūti pateikt.
Mākslīgā intelekta izstrādātāji ir panāk progresu. 7 pārsteidzošas vietnes, lai redzētu jaunākās mākslīgā intelekta programmasMākslīgais intelekts vēl nav HAL no 2001. gada: Kosmosa odiseja…, bet mēs esam nokļuvuši šausmīgi tuvu. Protams, kādu dienu tas varētu būt līdzīgs sci-fi katliem, kurus izcēris Holivuda ... Lasīt vairāk Mašīnu, kuras mēs būvējam, un problēmu, kuras tās var atrisināt, darbības joma ir arvien pieaug. 1997. gadā Deep Blue varēja spēlēt šahu augstākā līmenī nekā cilvēka lielmeistars. 2011. gadā IBM Watson varēja pietiekami dziļi un pietiekami ātri lasīt un sintezēt informāciju, lai pārspētu labāko cilvēku spēlētāji pie atvērtu jautājumu un atbilžu spēles, kas pilna ar puns un vārdu spēli - tas ir liels progress četrpadsmit gados.
Šobrīd Google ir lieli ieguldījumi dziļu mācību izpētē, tehnika, kas ļauj izveidot jaudīgus neironu tīklus, veidojot vienkāršāku neironu tīklu ķēdes. Šis ieguldījums ļauj tai gūt nopietnus panākumus runas un attēla atpazīšanā. Viņu jaunākais ieguvums šajā apgabalā ir Deep Learning startup ar nosaukumu DeepMind, par kuru viņi samaksāja aptuveni 400 miljonus USD. Kā daļu no darījuma noteikumiem Google piekrita izveidot ētikas padomi, lai nodrošinātu, ka viņu AI tehnoloģija tiek izstrādāta droši.
Tajā pašā laikā IBM izstrādā Watson 2.0 un 3.0 - sistēmas, kas spēj apstrādāt attēlus un video, un argumentē secinājumu aizstāvēšanu. Viņi sniedza vienkāršu, agrīnu Vatsona spēju demonstrēt argumentus par un pret tēmu zemāk esošajā video demonstrācijā. Rezultāti ir nepilnīgi, taču iespaidīgs solis neatkarīgi no tā.
Neviena no šīm tehnoloģijām pati par sevi šobrīd nav bīstama: mākslīgais intelekts kā joma joprojām cenšas atbilst spējām, kuras apgūst mazi bērni. Datorprogrammēšana un AI dizains ir ļoti sarežģīta, augsta līmeņa kognitīvā prasme, un tas, iespējams, būs pēdējais cilvēka uzdevums, kurā mašīnas apgūst prasmes. Pirms mēs nokļūsim šajā punktā, mums būs arī visuresošas mašīnas kas var braukt Lūk, kā mēs nonāksim pasaulē, kurā piepildītas automašīnas bez autovadītājiemBraukšana ir nogurdinošs, bīstams un prasīgs uzdevums. Vai to kādu dienu varētu automatizēt Google bez vadītāja automašīnas tehnoloģija? Lasīt vairāk , praktizē medicīnu un likumuun, iespējams, arī citas lietas ar nopietnām ekonomiskām sekām.
Laiks, kas vajadzīgs, lai nonāktu līdz sevis pilnveidošanas centram, ir atkarīgs tikai no tā, cik ātri mums ir labas idejas. Pazīstami grūti ir prognozēt šāda veida tehnoloģiskos sasniegumus. Nešķiet nepamatoti, ka mēs varētu izveidot spēcīgu AI divdesmit gadu laikā, bet arī nešķiet nepamatoti, ka tas varētu aizņemt astoņdesmit gadus. Katrā ziņā tas notiks galu galā, un ir iemesls uzskatīt, ka tad, kad tas notiks, tas būs ārkārtīgi bīstams.
Tātad, ja mēs atzīstam, ka tā būs problēma, ko mēs varam darīt ar to? Atbilde ir pārliecināties, ka pirmās inteliģentās mašīnas ir drošas, lai tās varētu ielādēt līdz ievērojamam intelekta līmenim, un pēc tam pasargātu mūs no nedrošām mašīnām, kas izgatavotas vēlāk. Šī “drošība” tiek definēta, daloties ar cilvēciskām vērtībām un ar vēlmi aizsargāt un palīdzēt cilvēcei.
Tā kā mēs faktiski nevaram sēdēt un programmēt cilvēciskās vērtības mašīnā, iespējams, būs jāprojektē lietderības funkcija, kas prasa, lai mašīna novērot cilvēkus, secināt mūsu vērtības un tad mēģināt tās maksimizēt. Lai padarītu šo attīstības procesu drošu, var būt noderīgi attīstīt arī speciāli izstrādātu mākslīgo intelektu nē ir preferences attiecībā uz to lietderības funkcijām, ļaujot mums tās izlabot vai izslēgt bez pretestības, ja tās attīstības laikā sāk maldīties.
Daudzas problēmas, kuras mums jāatrisina, lai izveidotu drošu mašīnu izlūkošanu, matemātiski ir sarežģītas, taču ir iemesls uzskatīt, ka tās var atrisināt. Ar šo jautājumu strādā vairākas dažādas organizācijas, ieskaitot Cilvēces institūta nākotne Oksfordāun Mašīnizlūkošanas pētniecības institūts (kuru finansē Pēteris Thiels).
MIRI ir īpaši ieinteresēts attīstīt matemātiku, kas nepieciešama draudzīgas AI izveidošanai. Ja izrādās, ka mākslīgā intelekta palaišana ir iespējama, tad šāda veida attīstību Pirmkārt, ja draudzīga AI tehnoloģija ir veiksmīga, tā var būt vienīgā vissvarīgākā lieta, kas cilvēkiem ir kādreiz darīts.
Vai jūs domājat, ka mākslīgais intelekts ir bīstams? Vai jūs uztrauc tas, ko varētu radīt AI nākotne? Dalieties savās domās komentāru sadaļā zemāk!
Attēlu kredīti: Lwp Kommunikācija Via Flickr, “Neironu tīkls“, Pēc fdecomite,” img_7801“, Stīvs Raitvuds,“ E-Volve ”, Keoni Kabrāla,“jauns_20x“, Autors Roberts Kudmors,“Saspraudes“, Autors Klifords Wallace
Rakstnieks un žurnālists, kas atrodas dienvidrietumos, Andre ir garantēts, ka tas joprojām darbosies līdz 50 grādiem pēc Celsija un ir ūdensizturīgs līdz divpadsmit pēdu dziļumam.
