Reklāma
27. janvārī Google paziņoja, ka AlphaGo, an mākslīgais intelekts Kas nav mākslīgais intelektsVai inteliģenti, jūtīgi roboti gatavojas pārņemt pasauli? Ne šodien - un varbūt arī nekad. Lasīt vairāk kuru izstrādāja tās meitasuzņēmums DeepMind, piecu spēļu mačā bija pieveicis Eiropas Go čempionu Fanu Hui.
Jūs, iespējams, esat dzirdējis par šīm ziņām, jo tās veido virsrakstus visā pasaulē, bet kāpēc cilvēkiem tas tik ļoti rūp? Ko tas viss nozīmē? Ja neesat pazīstams ar Go spēli vai tās nozīmi mākslīgajam intelektam, iespējams, jūtaties mazliet apmaldījies.
Neuztraucieties, mēs esam jūs pārklājuši. Šeit ir viss, kas jums jāzina par sasniegumu un to, kā tas ietekmē regulārus cilvēkus, piemēram, jūs un mani.
Spēles gājiens: vienkāršs, tomēr komplekss
Go ir sena ķīniešu stratēģijas spēle, kurā divi spēlētāji cīnās par teritorijas sagūstīšanu. Pēc kārtas katrs spēlētājs - viens balts, otrs - melns - novieto akmeņus 19 x 19 režģa krustojumos. Kad akmeņu grupa ir pilnībā ieskauta otra spēlētāja akmeņiem, tie tiek “notverti” un noņemti no galda.
Spēles beigās katra tukšā vieta ir “pieder” spēlētājam, kas to ieskauj. Katra spēlētāja punktu skaits tiek noteikts, pamatojoties uz to, cik daudz teritorijas viņam pieder (t.i., cik daudz tukšas vietas viņš ir ieskauj), kā arī pretinieka gabalu skaitu, kas tika notverti spēles laikā.

Lai gan vairums cilvēku domā, ka šahs ir stratēģisko spēļu karalis, Go patiesībā ir daudz sarežģītāks. Saskaņā ar Wikipedia, ir 10761 iespējamās Go spēles, salīdzinot ar 10120 aplēstās iespējamās šaha spēles.
Šī sarežģītība kopā ar dažiem ezotēriskiem noteikumiem un uzsvaru uz spēlēšanu pēc instinkta padara Go par īpaši sarežģītu spēli datoriem, lai viņi varētu mācīties un spēlēt augstā līmenī.
Neticami pasaule, kurā spēlē AI
Lielajā lietu shēmā mākslīgā intelekta izstrāde, kas spēlē spēli, nešķiet ļoti vērtīgs vajāšana, it īpaši, ja IBM Watson AI jau strādā, lai palīdzētu uzlabot veselības aprūpi - joma, kurai nepieciešama visa iespējamā palīdzība gūt. Tad kāpēc Google pavadīja tik daudz stundu un dolāru, lai izveidotu Go-playing AI?
Vienā līmenī tas palīdz AI pētniekiem izdomāt labāko veidu, kā iemācīt datoriem darīt lietas. Ja varat iemācīt datoru, kā atrisināt labākos gājienus Dambrete vai Tic-Tac-Toe spēlē, jūs varētu gūt ieskatu cita datora mācīšanā, kā iesakiet filmas Netflix 4 mašīnmācīšanās algoritmi, kas veido jūsu dzīviJūs, iespējams, to neaptverat, bet mašīnmācīšanās jau ir visapkārt, un tā var radīt pārsteidzošu pakāpi jūsu dzīvē. Netici man? Jūs varētu būt pārsteigts. Lasīt vairāk , tūlīt pārtulkot runu vai paredzēt zemestrīces.
Daudziem AI lietojumiem, ko mēs līdz šim esam redzējuši, būtu ieguvums no uzlabotām problēmu risināšanas un modeļa iegūšanas spējām, kurām arī ir nozīme efektīvu AI spēlēšanā.
Šaha čempions AI Deep Blue strādāja, izmantojot milzīgu skaitļošanas jaudas un brutālā spēka paņēmienus, lai novērtētu visus iespējamos nākamos gājienus - līdz 200 000 000 pozīcijām sekundē. Un, kaut arī šī stratēģija bija pietiekami efektīva, lai pieveiktu bijušo pasaules šaha čempionu, tas nav īpaši “cilvēkam līdzīgs” veids, kā spēlēt šahu. Tas arī prasa programmētājiem “izskaidrot” AI spēles noteikumus.
Pavisam nesen tika izstrādāts process ar nosaukumu dziļa mācīšanās, kas būtībā pavēra ceļu datoriem sevi mācīt, un tas pilnībā mainīja sacensības par mākslīgo intelektu Microsoft vs Google - kurš vada mākslīgā intelekta sacīkstes?Mākslīgā intelekta pētnieki gūst jūtamu progresu, un cilvēki atkal sāk nopietni runāt par AI. Divi titāni, kas vada mākslīgā intelekta sacensības, ir Google un Microsoft. Lasīt vairāk .
Dziļi mācoties, dators var iegūt noderīgus modeļus no datiem - tā vietā, lai programmētāji viņiem pateiktu, kādi modeļi ir jāmeklē, un izmantot šos modeļus, lai optimizētu savus lēmumus. Ja padziļināta mācīšanās ir veiksmīga, AI pat var atklāt modeļus, kas ir efektīvāki par to, ko mēs varam atpazīt kā cilvēku.
Šāda veida mācīšanās tika demonstrēta pagājušajā gadā, kad Google piederošā AI pētījumu firma DeepMind atklāja AI, kas iemācīja spēlēt 49 dažādus Atari spēles Atari Arcade - spēlējiet retro videospēles HTML5 formātā [MUO Gaming]Ikviens, kurš šodien spēlē videospēles, ir parādā milzīgu pateicības parādu Atari un dibinātājiem un inženieriem, kuri strādāja uzņēmumā tā veidošanās gados. Atari bija atbildīgs par daudziem ... Lasīt vairāk pēc tam, kad tam ir dota tikai jēla izejviela. (Iepriekš jūs varat redzēt, kā mācās spēlēt Breakout.)
Process ir tāds pats kā videospēles apgūšana bez apmācības vai paskaidrojuma. Jūs kādu brīdi vērojat, pēc tam mēģiniet nospiest nejaušas pogas, pēc tam sākat izdomāt lietas, izstrādāt stratēģijas un galu galā doties uz izcilību.
Un izcili to arī izdarīja. DeepMind AI absolūti iznīcināja profesionāla līmeņa cilvēku pretiniekus dažās no šīm spēlēm, piemēram, Video Pinball. Citās spēlēs, tai skaitā Pac-Man kundzei, tā bija ievērojami sliktāka, taču tās kopējais rekords bija ļoti iespaidīgs.
AlphaGo: nākamais AI līmenis
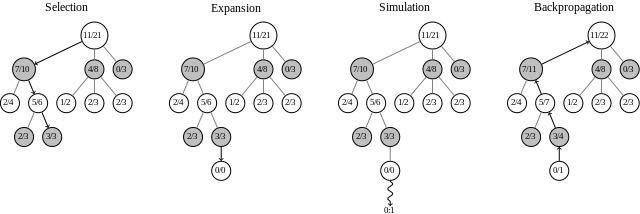
AlphaGo, dators, kas pieveica Fan Hui at Go, izmantoja šo dziļo mācību stratēģiju, lai piecos mačos kļūtu nepārspēts.
Tā vietā, lai izmantotu brutālu spēku aprēķināšanu, piemēram, Deep Blue, AlphaGo noteica savu nākamo gājienu, izmantojot mācībās apgūto, lai ierobežojiet potenciāli efektīvo gājienu apjomu, pēc tam veicot simulācijas, lai redzētu, kuri gājieni visdrīzāk bija pozitīvi iznākumi.
Divas dažādas neironu tīkli Jaunākās datortehnoloģijas, kas jums jāredz, lai ticētuIepazīstieties ar dažām jaunākajām datortehnoloģijām, kas nākamo gadu laikā ir pārveidotas elektronikas un personālo datoru pasaulē. Lasīt vairāk , politikas tīkls un vērtību tīkls strādāja kopā, lai novērtētu gājienus un katrā pagriezienā izvēlētos labāko.
Go sarežģītības dēļ brutāla spēka pieeja visās iespējamās kustībās vienkārši nav iespējama, kā tas ir šahā. Tātad AlphaGo izmantoja zināšanas, kuras tā ieguva apmācības posmā, kas sastāvēja no 30 miljonu gājienu skatīšanās, ko veica cilvēku eksperti, iemācoties paredzēt savus gājienus, izstrādājot savas stratēģijas un spēlējot pret sevi tūkstošiem cilvēku reizes.
Izmantojot pastiprinošās mācības, tā lēmumu pieņemšanas procesi tika attīstīti un nostiprināti, līdz AlphaGo kļuva par labāko Go-playing AI pasaulē. 500 spēlēs pret vismodernākajiem Go datoriem tas uzvarēja no tiem 499 - pat pēc tam, kad šīm programmām bija piešķirts četru virzienu iesākums.
Un, protams, AlphaGo pārspēja Fan Hui, pašreizējo Eiropas Go čempionu. Uzvara faktiski tika sasniegta 2015. gada oktobrī, taču paziņojums tika aizkavēts līdz brīdim, kad tika publicēts DeepMind pētniecības darbs Daba. Martā AlphaGo uzņems Lī Sedolu, kurš ir dominējošākais spēlētājs pasaulē desmit gadu laikā.
Labi, ko tas viss nozīmē?
Kāpēc tas veido virsrakstus visā pasaulē? Vairāku iemeslu dēļ.
Pirmkārt, daudzi cilvēki uzskatīja, ka tas nav iespējams ar pašreizējām tehnoloģijām. Lielākā daļa aplēses apgalvoja, ka AI vēl vismaz desmit gadus nepārspēs pasaules klases Go spēlētāju. AlphaGo vērtību tīkli var novērtēt jebkuru pašlaik spēlēto Go spēli un paredzēt iespējamo uzvarētāju - problēma, par kuru Google saka “tik smagi tas bija domājams, ka tas nav iespējams. ”

Otrkārt, ļoti svarīgi ir tas, ka tika izmantota dziļa un neatkarīga mācīšanās. Tas parāda, ka pašreizējais mākslīgais intelekts var apkopot datus, iegūt modeļus, iemācīties tos paredzēt modeļus, un galu galā izstrādā problēmu risināšanas stratēģijas, kas ir pietiekami sarežģītas un efektīvas, lai pieveiktu a pasaules klases cilvēks.
Un, lai arī laimests Go nemainīs pasauli, tas, ka dators spēja nākt klajā ar šāda līmeņa stratēģiju, izmantojot savus mācību algoritmus, ir ļoti iespaidīgs.
Tieši šī dziļā mācīšanās ir AI pētnieki patiešām satraukti par AlphaGo. Daudzi uzskata, ka patstāvīga mācīšanās ir pirmais solis ceļā uz spēcīgs mākslīgais intelekts. Spēcīga AI attiecas uz datoru, kas spēj atrisināt intelektuālos uzdevumus līdzvērtīgi cilvēkiem (kas ir neticami grūti, galvenokārt cilvēka smadzeņu sarežģītības un efektivitātes dēļ). Tas ir tāds AI veids, kādā jūs redzat daudzas zinātniskās fantastikas filmas Uzmanību, internets! Labākās filmas par mākslīgo intelektuHolivuda gadu gaitā ir izlaidusi daudz lielisku filmu, kurās pētīti mākslīgā intelekta jautājumi, un šeit ir 10 labākās filmas par AI, kuras mēs iesakām pārcelt debesīs un zemē uz ... Lasīt vairāk .

Tieši šī iemesla dēļ tādu AI radīšana, kas var izturēties cilvēciski, ir tik liels darījums. Modeļu ieguve un stratēģiju izstrāde ir kaut kas tāds, ko mēs darām visu laiku, un lēmumu pieņemšanā neizmantojam brutāla spēka metodes.
Ir ļoti grūti iegūt datoru, lai to izdarītu bez daudzām norādēm, taču, pateicoties AlphaGo, mēs tagad zinām, ka spēcīga AI nav tikai iespējama, bet tuvāk, nekā mēs domājām.
Protams, Go-playing AI joprojām ir tālu no vispārēji inteliģentās AI. Tas izdara tikai vienu lietu, kas ir tikpat vienkārša, kā var iegūt mākslīgais intelekts - pat Atari spēlējošā AI bija spēja spēlēt 49 dažādas spēles Nākotnes video spēļu AI jūs nopietni izklaidēsVideo spēļu AI vēl nav viss tik lieliski. Tomēr ar neseno tehnoloģiju attīstību tas drīz var mainīties. Lasīt vairāk - bet AlphaGo efektīvā patstāvīgā mācīšanās varētu būt pirmais solis uz būtiskām AI paradigmas izmaiņām.
Ko tu domā?
Nav šaubu, ka AlphaGo uzvara pār Fanu Hui ir svarīga, bet par to, vai tas ir vērts pasaules virsrakstos, ir jāapspriež.
Vai jūs domājat, ka tas ir liels darījums? Vai mēs esam vienu soli tuvāk robota apokalipse Microsoft, mākslīgais intelekts un robotu apokalipseMicrosoft piešķir nopietnu izskatu autonomu robotu virknei. Vai cilvēkiem tas ir beigu sākums vai tikai vēl viens solis uz priekšu droša mākslīgā intelekta sasniegšanā? Lasīt vairāk ? Vai arī jūs neaizrauj AI, kas var vienkārši spēlēt spēli? Kopīgojiet savas domas zemāk un parunāsim par to.
Attēlu kredīti: iet spēle autors caur Shutterstock, Tatjana Belova, izmantojot vietni Shutterstock.com, Makiura caur Wikimedia Commons, Zerbor, izmantojot vietni Shutterstock.com
Dann ir satura stratēģijas un mārketinga konsultants, kurš palīdz uzņēmumiem radīt pieprasījumu un ved. Viņš arī blogus par stratēģiju un satura mārketingu vietnē dannalbright.com.


