Reklāma
Vai jūs ticat idejai, ka, tiklīdz kaut kas tiek publicēts internetā, tas tiek publicēts uz visiem laikiem? Nu, šodien mēs šo mītu kliedēsim.
Patiesība ir tāda, ka daudzos gadījumos ir pilnīgi iespējams izdzēst informāciju no interneta. Protams, ir ieraksts par vietnēm, kas ir izdzēstas, ja meklējat vietnē Wayback mašīna, pa labi? Jā, absolūti. Wayback mašīnā ir ieraksti par Web lapām, kas meklējami daudzos gados, - lapas, kuras neatradīsit, izmantojot Google meklēšanu, jo šī lapa vairs nepastāv. Kāds to izdzēsa vai vietne tika slēgta.
Tātad, tur nekā nevar apiet, vai ne? Informācija uz visiem laikiem tiks iegravēta interneta akmenī, vai to varēs redzēt paaudzēm paaudzē? Nu, ne tieši tā.
Patiesība ir tāda, ka, lai arī varētu būt grūti vai neiespējami iznīcināt galvenos jaunumus, kas no vienas ziņu vietnes vai emuāra izplatījušies uz citu, piemēram, vīruss, faktiski ir diezgan viegli pilnībā izdzēst tīmekļa lapu vai vairākas tīmekļa lapas no visiem esamības ierakstiem - noņemt šo lapu gan meklētājprogrammām, gan arī
Wayback mašīna Jaunā reversa mašīna ļauj jums vizuāli ceļot atpakaļ interneta laikāLiekas, ka kopš Wayback Machine palaišanas 2001. gadā vietņu īpašnieki ir nolēmuši izmest Alexa balstīto fonu un pārveidot to ar savu atvērtā koda kodu. Pēc pārbaudēm ar ... Lasīt vairāk . Protams, ir nozveja, bet mēs to sasniegsim.3 veidi, kā noņemt emuāru lapas no tīkla
Pirmā metode ir tāda, kuru izmanto vairums vietņu īpašnieku, jo viņi neko vairāk nezina - vienkārši izdzēš Web lapas. Tas var notikt tāpēc, ka esat sapratis, ka jūsu vietnē ir dublēts saturs, vai tāpēc, ka jums ir lapa, kuru nevēlaties parādīt meklēšanas rezultātos.
Vienkārši izdzēsiet lapu
Pilnīgas vietnes dzēšanas problēma ir tā, ka jūs jau esat izveidojis lapu vietnē tīklā, iespējams, būs saites no jūsu vietnes, kā arī ārējās saites no citām vietnēm uz šo konkrēto lappuse. Dzēšot to, Google nekavējoties atzīst šo jūsu lapu kā trūkstošu lapu.
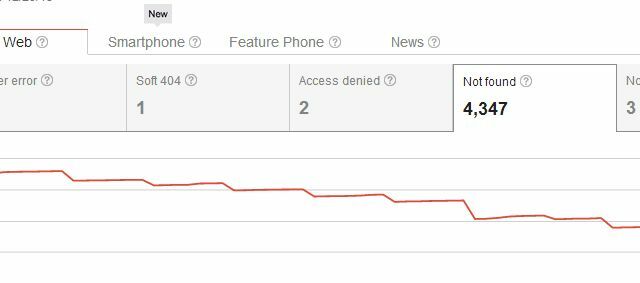
Dzēšot savu lapu, jūs ne tikai esat radījis problēmu ar rāpuļprogrammas kļūdām “Nav atrasts”, bet arī radījāt problēmu visiem, kas kādreiz ir izveidojuši saiti uz šo lapu. Parasti lietotāji, kas nokļūst jūsu vietnē no vienas no šīm ārējām saitēm, redzēs jūsu 404 lapu, kas nav liela problēma, ja izmantojat kaut ko līdzīgu Google pielāgotajam 404 kodam, lai sniegtu lietotājiem noderīgus ieteikumus vai alternatīvas. Bet jūs domājat, ka varētu būt arī graciozāki veidi, kā izdzēst lapas no meklēšanas rezultātiem, neizspiežot visus šos 404 esošajām ienākošajām saitēm, vai ne?
Nu, ir.
Lapas noņemšana no Google meklēšanas rezultātiem
Pirmkārt, jums vajadzētu saprast, ka, ja vietne, kuru vēlaties noņemt no Google meklēšanas rezultātiem, nav lapa no jūsu vietnes, tad jums veicas, ja vien nav juridisku iemeslu vai ja vietne ir ievietojusi jūsu personisko informāciju tiešsaistē bez jūsu atļauju. Ja tas tā ir, izmantojiet Google noņemšanas problēmu novēršanas rīks iesniegt pieprasījumu lapas noņemšanai no meklēšanas rezultātiem. Ja jums ir pamatots gadījums, iespējams, jūs gūsit zināmus panākumus, noņemot lapu - protams, ka jums varētu būt vēl lielāki panākumi tikai sazinoties ar vietnes īpašnieku Kā noņemt nepatiesu personisko informāciju internetāTiešsaistes privātums vairs netiek garantēts. Uzziniet, kā ziņot par vietni un noņemt personisko informāciju no interneta. Lasīt vairāk kā es aprakstīju, kā to izdarīt 2009. gadā.
Tagad, ja lapa, kuru vēlaties noņemt no meklēšanas rezultātiem, atrodas jūsu vietnē, jums veicas. Viss, kas jums jādara, ir izveidot robots.txt failu un pārliecinieties, vai esat atļāvis vai nu konkrētu lapu, kuru nevēlaties meklēšanas rezultātos, vai visu direktoriju ar saturu, kuru nevēlaties indeksēt. Lūk, kā izskatās vienas lapas bloķēšana.
Lietotāja aģents: * Neatļaut: /my-deleted-article-that-i-want-removed.html
Šādi var bloķēt robotprogrammatūru pārmeklēšanu uz visiem jūsu vietnes direktorijiem.
Lietotāja aģents: * Neatļaut: / saturs-par-personisko lietu /
Google ir lielisks atbalsta lapa kas var palīdzēt izveidot failu robots.txt, ja vēl nekad neesat to izveidojis. Tas darbojas ļoti labi, kā es nesen paskaidroju rakstā par sindicēšanas darījumu strukturēšana Kā apspriest sindikācijas piedāvājumus un aizsargāt jūsu meklēšanas klasifikācijuŠajās dienās viss dusmās ir sindicēšana. Bet pēkšņi jūs varētu atrast, ka sindikācijas partneris ir minēts augstāk nekā jūs meklēšanas rezultātos rezultātam stāstam, kuru jūs sākotnēji rakstījāt! Aizsargājiet meklēšanas klasifikāciju. Lasīt vairāk lai viņi jūs neapvainotu (lūdzot sindikācijas partneriem neļaut indeksēt viņu lapas, kurās esat sindicēts). Kad mans sindikācijas partneris piekrita to darīt, lapas, kuru saturs tika dublēts no mana emuāra, pilnībā pazuda no meklēšanas sarakstiem.
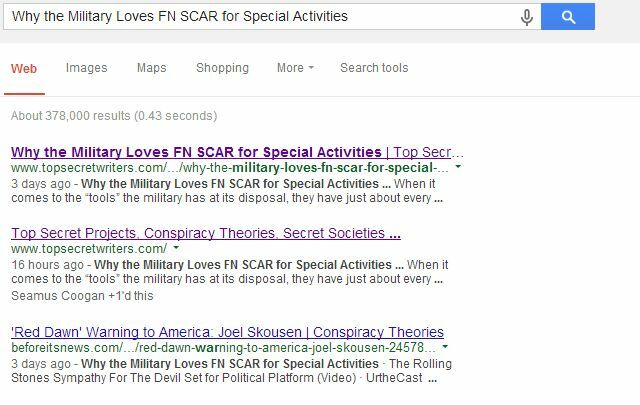
Trešajā vietā ir tikai galvenā vietne, kurā norādīti mūsu nosaukumi, bet mans emuārs tagad ir norādīts gan pirmajā, gan otrajā vietā; kaut kas būtu gandrīz neiespējams, ja vietne ar augstāku autoritāti paliktu dublētā lapa indeksēta.
Daudzi cilvēki neapzinās, ka to ir iespējams paveikt arī ar interneta arhīvu (Wayback Machine). Šīs ir līnijas, kas jāpievieno failam robots.txt, lai tas notiktu.
Lietotāja aģents: ia_archiver. Neatļaut: / parauga kategorija /
Šajā piemērā es saku interneta arhīvam noņemt no vietnes Wayback Machine visu, kas ir manas vietnes paraugu kategoriju apakšdirektorijā. Interneta arhīvā viņu izslēgšanas palīdzības lapā ir paskaidrots, kā to izdarīt. Viņi arī izskaidro, ka “Interneta arhīvs nav ieinteresēts piedāvāt piekļuvi tīmekļa vietnēm vai citiem interneta dokumentiem, kuru autori nevēlas, lai viņu materiāli būtu kolekcijā.”
Tas ir pretrunā ar vispārpieņemto uzskatu, ka viss, kas ievietots internetā, visu mūžību nonāk arhīvā. Nē - tīmekļa pārziņiem, kuriem pieder saturs, saturu var īpaši noņemt no arhīva, izmantojot robots.txt pieeju.
Noņemiet atsevišķu lapu ar meta tagām
Ja jums ir tikai dažas atsevišķas lapas, kuras vēlaties noņemt no Google meklēšanas rezultātiem, jums faktiski nav jāizmanto pieeja robots.txt vispār jūs varētu vienkārši pievienot pareizu “robotu” metatagu atsevišķām lapām un pateikt robotiem, lai tie neprogrammē un neseko saitēm kopumā lappuse.
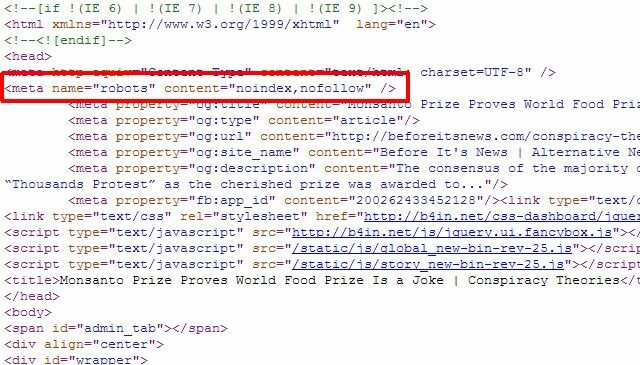
Varat izmantot meta “roboti”, lai apturētu robotus no lapas indeksēšanas, vai arī jūs varētu konkrēti pateikt Google robotam neindeksēt, lai lapa tiktu noņemta tikai no Google meklēšanas rezultātiem, un citi meklēšanas roboti joprojām varētu piekļūt lapai saturs.
Tas ir pilnībā atkarīgs no jums, kā jūs vēlaties pārvaldīt to, ko roboti dara ar lapu, un to, vai lapa tiek iekļauta sarakstā. Labāka pieeja varētu būt tikai dažām atsevišķām lapām. Lai noņemtu visu satura direktoriju, izmantojiet metodi robots.txt.
Ideja par satura noņemšanu
Šādi visa jēga “satura dzēšana no interneta” tiek pagriezta uz galvas. Tehniski, ja jūs noņemat visas savas saites uz savas vietnes lapu un noņemsit to no Google meklēšanas un Interneta arhīvā, izmantojot robots.txt tehniku, lapa visiem nolūkiem un mērķiem ir “izdzēsta” no interneta. Forši, ka, ja ir esošas saites uz šo lapu, tās joprojām darbosies, un jūs neizraisīsit 404 kļūdas šiem apmeklētājiem.
Tā ir “maigāka” pieeja satura noņemšanai no interneta, pilnībā neizjaucot vietnes pašreizējo saišu popularitāti visā internetā. Visbeidzot, tas, kā jūs pārvaldāt, kādu saturu apkopo meklētājprogrammas un interneta arhīvs, ir atkarīgs no jums, bet vienmēr atcerieties, ka, neraugoties uz to, ko cilvēki saka par tiešsaistē ievietoto lietu dzīves ilgumu, tas tiešām ir pilnībā jūsu ziņā kontrole.
Ryanam ir bakalaura grāds elektrotehnikā. Viņš ir strādājis 13 gadus automatizācijas inženierijā, 5 gadus IT jomā un tagad ir Apps Engineer. Bijušais MakeUseOf galvenais redaktors, viņš uzstājās nacionālajās datu vizualizācijas konferencēs un tiek demonstrēts nacionālajā televīzijā un radio.

